Introduction
Materials and Methods
Cultivation Conditions
Data Collection
LSTM
Data Interpolation and Preprocessing
Results and Discussion
Introduction
Farmers actively control the growth environment, such as temperature, light, relative humidity, and CO2 concentration, using a greenhouse. Among the plant environmental factors, photosynthesis efficiency is a crucial factor for growing crops in greenhouses. To improve the productivity of cultivation, it is necessary to maximize photosynthesis of crops (Cock and Yoshida, 1973). Photosynthesis is influenced by variable environmental factors, such as temperature, relative humidity, and CO2 concentration (Kaplan et al., 1980; Davison, 1991; Lawlor, 1995). Among the environmental factors, CO2 is consumed in the process of photosynthesis as a reactant, so an additional CO2 supply can promote photosynthesis (Gifford and Rawson, 1994; Maroco et al., 2002). Therefore, control of CO2 concentration is important. In light of this, studies have been conducted to maximize photosynthesis using CO2 fertilization (Oechel et al., 1994; Donohue et al., 2013; Lotfiomran et al., 2016). When CO2 is fertilized, it promotes crop growth and increases productivity (McGrath and Lobell, 2013). The amount of fertilized CO2 and the productivity of crops do not have a linear relation, so finding the optimal amount of CO2 is a matter of fact for precision agriculture (Linker et al., 1998; Kläring et al., 2007; Graamans et al., 2018). However, in greenhouse conditions, the CO2 concentration is affected both by structural factors such as the ventilation rate and by environmental factors such as temperature, so it is not easy to saturate the optimal CO2 concentration (Boulard et al., 2002; Roy et al., 2002).
Individual photosynthetic properties of a crop can be measured using photosynthesis systems to determine the optimal amount of CO2 supply according to the growing environment (William et al., 1986; Sharma-Natu et al., 1998; Jung et al., 2016). However, the crops make a canopy in most plant production systems. Since canopy photosynthesis is different from individual photosynthesis, modeling individual photosynthesis and applying it to a greenhouse make a disjunction with actual photosynthesis. In this case, the amount of consumed CO2 can be measured instead of canopy photosynthesis (Goto, 2012; Jung et al., 2016). In insulated spaces such as plant factories, there is little environmental change. Therefore, the CO2 consumption of the canopy can be measured easily, making efficient CO2 fertilization possible. However, environmental fluctuations within a greenhouse are more complicated than a plant factory since greenhouses are not completely insulated (Graamans et al., 2018). In addition, plant growth factors should be considered along with various greenhouse environments because CO2 concentrations are also affected by crop growth conditions. Therefore, it is not easy to predict the CO2 concentration of a greenhouse.
Recently, deep learning has been studied because of its ability to achieve high-level abstraction from raw data (Mnih et al., 2015; Silver et al., 2016). The base of a deep learning algorithm is an artificial neural network (ANN), and it has various structures depending on the algorithm. For weather data, ANNs have been used to analyze nonlinear relationships of the environment (Hu et al., 2016; Liu et al., 2016). In particular, estimation of greenhouse CO2 was also studied using ANNs (Moon et al., 2018b). In the previous study, it was verified that an ANN can be trained to find the relationship between CO2 concentrations and environmental factors. However, the estimation was only in contemporary conditions, so it was difficult to use for active control, such as CO2 fertilization.
As a part of deep learning, recurrent neural networks (RNNs) are used to analyze sequential data such as voice and video (Han et al., 2017; Wang et al., 2017; Zhao et al., 2018). In particular, among the RNN algorithms, long short-term memory (LSTM) has the advantage of analyzing data from a relatively long period (Greff et al., 2017). In greenhouse conditions, the electrical conductivity and ion concentrations of nutrient solutions were predicted using LSTM (Moon et al., 2018a, Moon et al., 2019). Similar to root-zone factors, the CO2 concentration in greenhouses also is influenced by accumulated changes in other environmental factors. The objective of this study was to predict CO2 concentrations using environmental factors in greenhouses via LSTM.
Materials and Methods
Cultivation Conditions
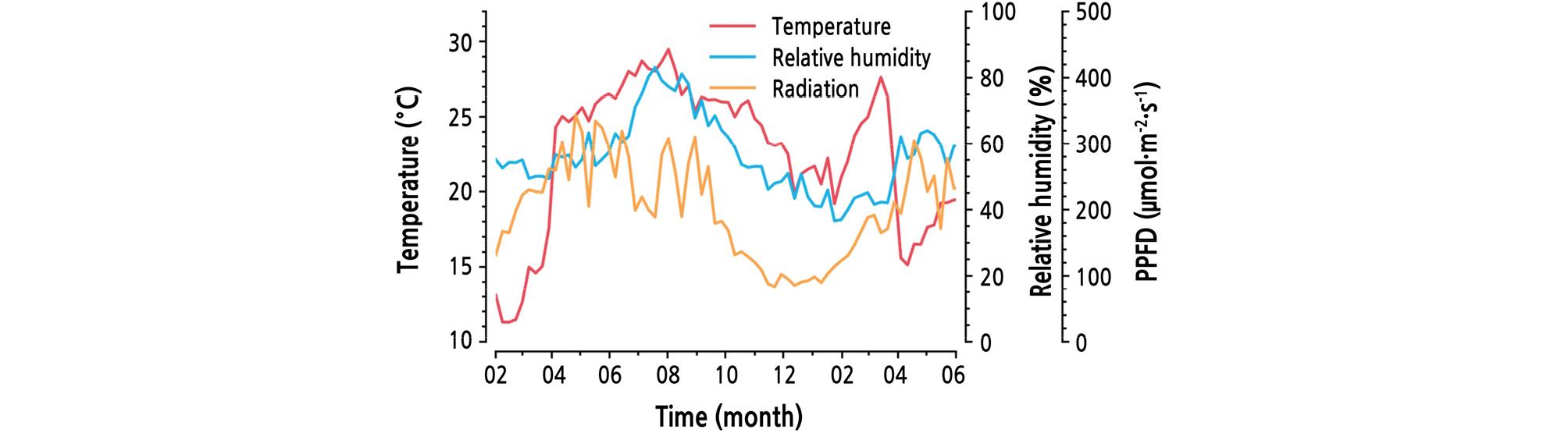
A double-span arch-type plastic house (34.4 W × 30.0 L × 5.7 H, m, 1,032 m2) located in Boryeong, Korea (36°23'34"N, 126°29'12"E) was used for the experiment. The greenhouse-covering material consisted of 0.15-mm-thick polyolefin films. The light transmittance was approximately 92%. Since diverse experiments were carried out, the environmental changes varied (Fig. 1). In the winter season, the inside temperature was maintained at 251°C using a hot-water heating system. There were periods of low temperatures for flower bud differentiation during the cultivation. The ventilation system was automatically opened at a set point of 27°C. CO2 fertilization started on Dec 10, 2016. One hundred 4-year-old mango trees (Mangifera indica L. cv. Irwin) were planted in 0.8-m-diameter pots. The planting density was 6.25 plant·m-2. The organic content of the soil ranged from 38 to 120 g·kg-1. A drip irrigation system was used for watering.
Data Collection
A complex sensor module developed by Korea Electronics Technology Institute (Seongnam, Korea) was used to measure environmental factors (Table 1). Nine sensor modules were evenly installed in the greenhouse. The sensor measured illumination and converted it into photosynthetic photon flux density (PPFD) using a conversion factor (54 lx·µmol-1·m2·s). Greenhouse environmental data were measured every 10 min from February 2, 2017 to May 31, 2018. Weather data for the same period were gathered at Boryeong Meteorological Station.
Table 1. Ranges of environmental data used as inputs of long short-term memory (LSTM). The values represent the averaged data measured by nine sensors in the greenhouse. PPFD was calculated using a conversion factor (54 lx⦁μmol-1⦁m2⦁s)
LSTM
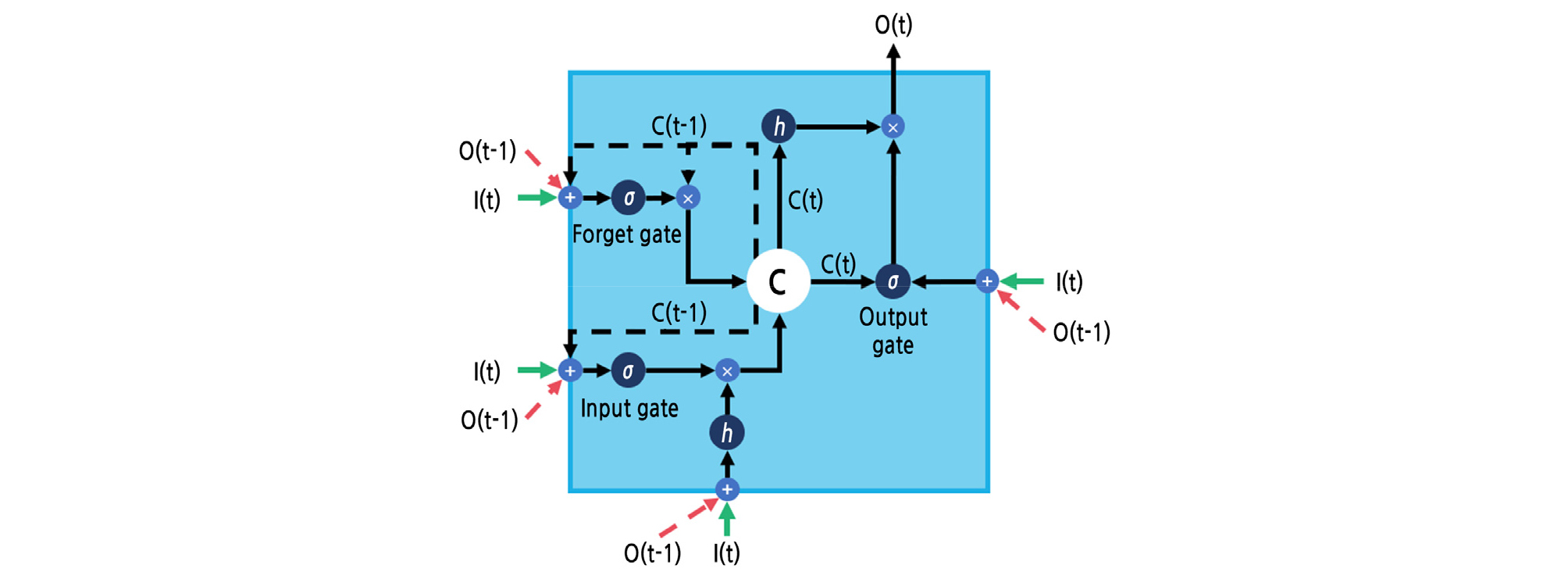
LSTM solved the vanishing gradient problem of RNNs, so LSTM can memorize long-period sequences (Hochreiter and Schmidhuber, 1997). The LSTM consists of a cell with several gates (Fig. 2). The symbols h and σ represent the input activation function and gate activation function, respectively. LSTM adds previous data to the cell state, so there is no vanishing gradient or exploding gradient problem. Computationally, LSTM accepts current input and previously processed output at the same time. The accepted values are operated at the gates. Processed information is saved in the cell state, so sequences can be memorized. Gates of LSTM are divided into three parts. The input gate determines how to select the input and output. The forget gate determines how much previous information should be forgotten. The output gate mixes the cell state with input data. LSTM yields the final output when the computation step reaches the predetermined time step.
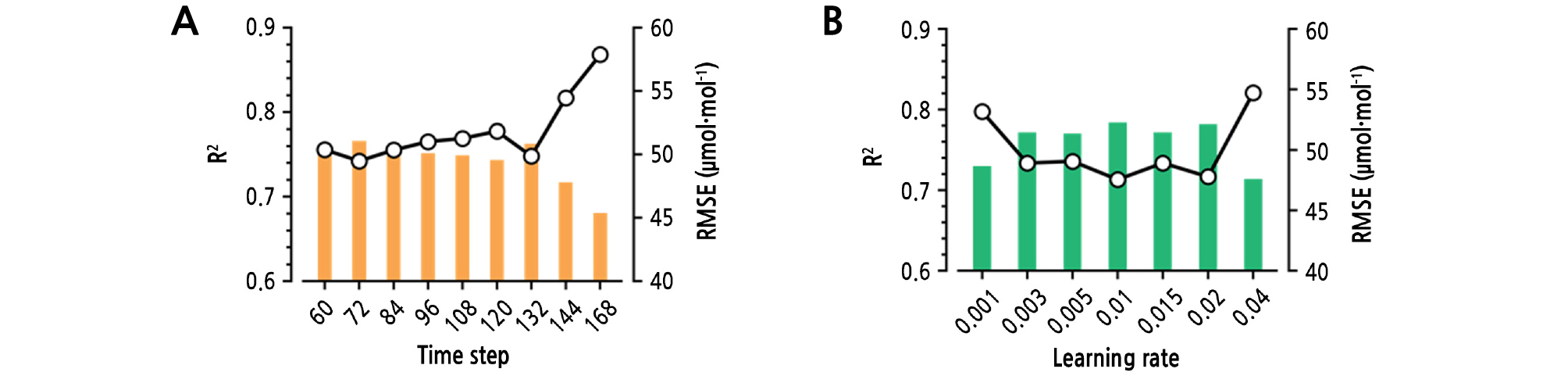
An RNN has hidden layers similar to an ordinary ANN. Input and output activation functions were set to the hyperbolic tangent function, and the gate activation function was set to the sigmoidal function. The number of perceptrons was variously combined to determine the optimal structure. In this study, previous environmental data were used as input, and the average CO2 concentration of the nine sensors was used as output. The learning rate and the time step of LSTM were varied to determine the optimal value, and the output length was set to 12 (Fig. 3). AdamOptimizer was used to train the LSTM (Kingma and Ba, 2014). The hyperparameters for the LSTM and AdamOptimizer were set to empirically used values (Table 2). For regularization, layer normalization was also used (Ba et al., 2016). Generally, neural networks are set to minimize cost (Rumelhart et al., 1988). In this study, the mean squared error (MSE) instead of the root mean squared error (RMSE) was used as a cost for reducing computation. The coefficient of determination (R2) was used for training and test accuracy. RMSE was used for verifying model robustness. TensorFlow (v. 1.12.0) was used for computation (Abadi et al., 2016).
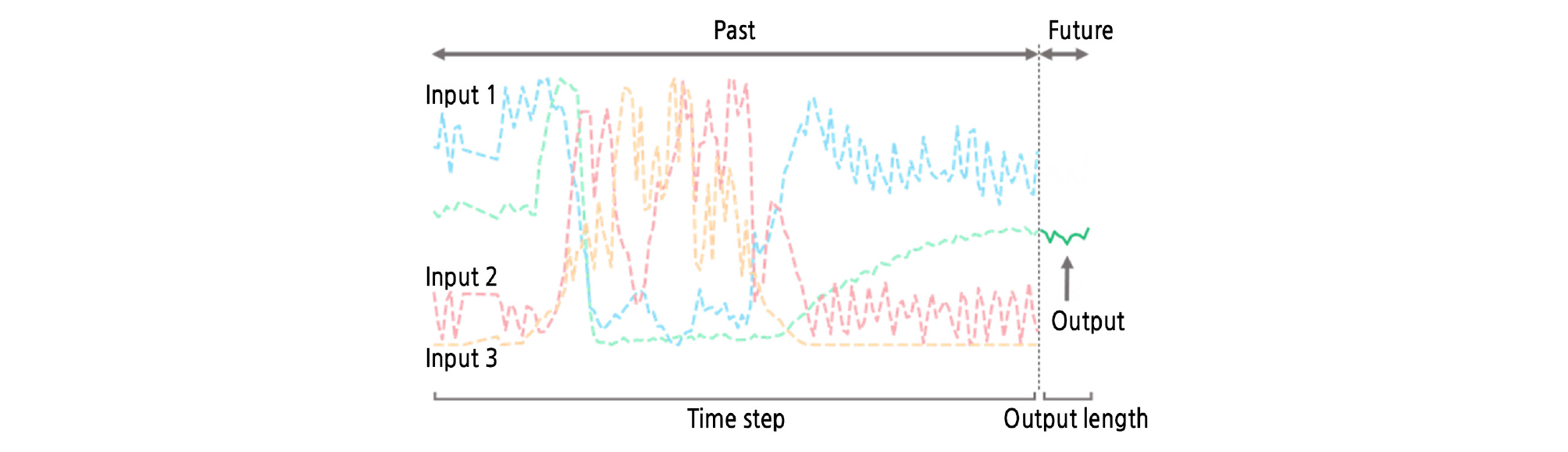
Table 2. Hyperparameters for LSTM and AdamOptimizer
Data Interpolation and Preprocessing
Missing data were filled using interpolation methods. Linear interpolation was used for the missing data with an interval of less than 30 min, while MLP was used for the missing data with longer intervals. Completely missing data, which cannot be inferred using other contemporary environmental factors, were filled with the data from 1 week prior. To train the LSTM, the data were normalized from 0 to 1 to improve training efficiency. The dataset was prepared according to the time step and output length. All datasets had an interval of 10 min and were periodically divided into training and test data. To prevent the test information from being included in the training data, the training dataset did not include the period of the test dataset. That is, the datasets were divided without overlapping. In this study, the number of datasets was 69,684, and five-fold cross validation was conducted using a training and test dataset.
Results and Discussion
Results and Discussion
The trained LSTM showed acceptable performance in the prediction of greenhouse CO2 concentrations. In this study, the optimal time step was 72 (720 min; data interval: 10 min), and the optimal learning rate was 0.01 (Fig. 4). The test accuracies tended to decrease with the extension of the time step. Various learning rates did not change the test accuracies except 0.001 and 0.04. The LSTM is known for solving the vanishing gradient problem in recurrent neural networks (Hochreiter and Schmidhuber, 1997). In particular, the LSTM can deal with >1,000 time steps in natural language processing (Wu et al., 2016). Therefore, the information exceeding 720 min was not meaningful for predicting greenhouse CO2 concentrations. In fact, CO2 concentrations change in a short time, so a 10-min interval could be too long for prediction (Lashof, 1989; Moon et al., 2018b). Therefore, a long time step with a short interval could yield higher accuracy. However, the trained LSTM with a time step of 72 and a 0.01 learning rate yielded an R2 of almost 0.8, and the accuracy was higher than the previous applications of LSTM (Rußwurm and Körner, 2017; Zhang et al., 2018; Moon et al., 2019). Since the highest accuracy was yielded with a time step of 72 and a 0.01 learning rate, subsequent experiments were conducted using the same hyperparameters.
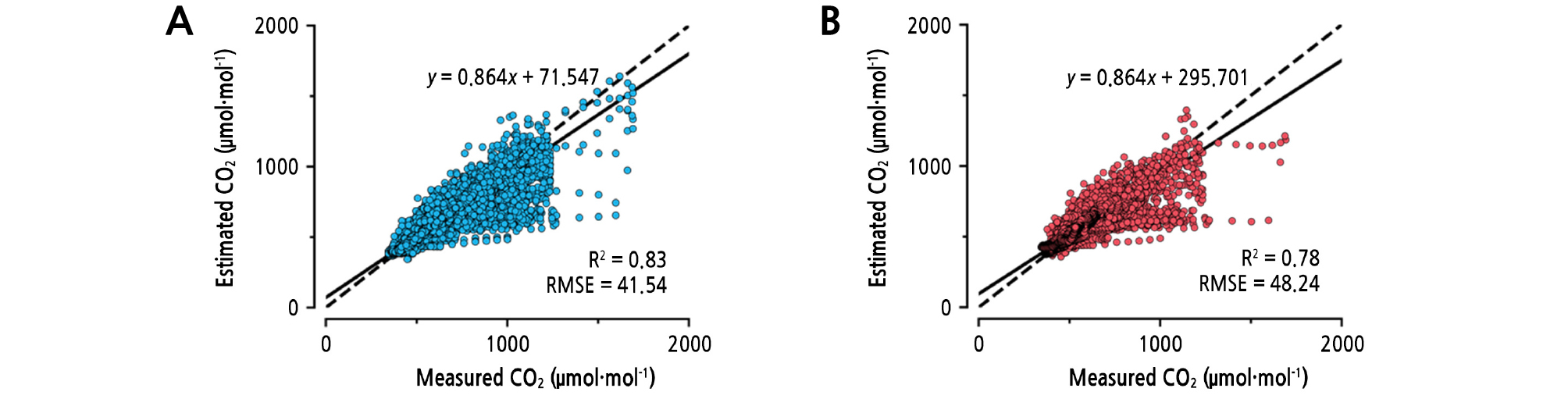
For the validation, the average training accuracy and test accuracy of all five validations was R2 = 0.83 and 0.78, respectively (Fig. 5). The graph shows some variance, but the R2 and RMSE were adequate. The trained LSTM showed the tendency to underestimate the CO2 concentrations. CO2 concentrations in the range around 1,000 µmol·mol-1 were especially underestimated. High CO2 concentrations usually occurred when CO2 was fertilized unnaturally, so they could not be predicted using only environmental factors. More various data such as controls, workbooks, or images could increase model accuracy (Kamilaris and Prenafeta-Boldú, 2018). In this study, plant growth data were not used for investigating whether the greenhouse environment could be predicted only with environment factors. Therefore, adding plant growth can improve model robustness because the greenhouse environment is disturbed by plants. The external CO2 concentration is almost constant and may help a bit. Since the trained LSTM yielded a sequence of outputs using multiple kinds of inputs, conventional algorithms such as ARIMA models, multivariate regression, or multilayer perceptrons could not be trained in the same training condition.
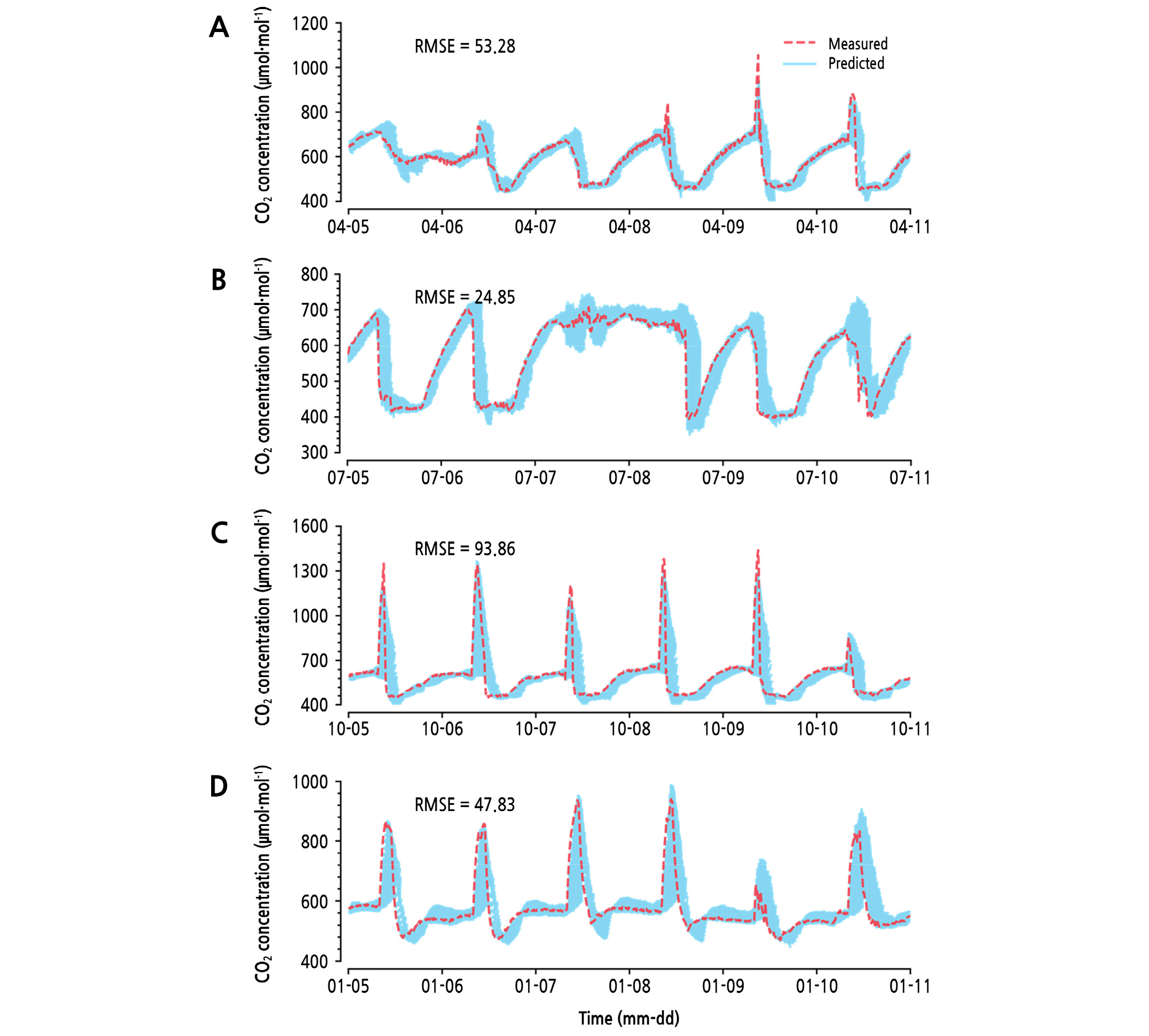
For a seasonal comparison, the LSTM showed the best accuracy from July 5 to 11, 2017 (Fig. 6). The prediction had especially high variance in autumn from October 5 to 11, 2017. Generally, the predicted area showed the possibility of underestimating fertilized CO2. In particular, a previous pattern was repeated as outputs of LSTM. One of the characteristics of LSTM is to accept previous information, so it can be seen that the previous information had a more influential effect on the prediction prior to the inference of the future changes. Therefore, some generative models could be more effective than LSTM in the case of long-term prediction (Sutskever et al., 2014; Oord et al., 2016).
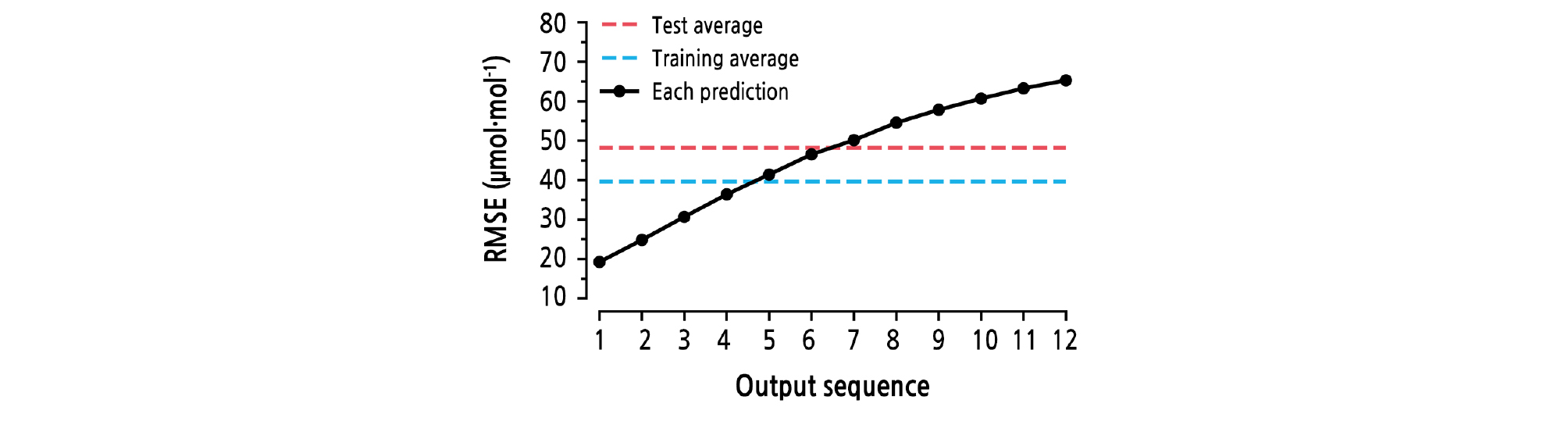
RMSEs of time-series outputs showed an increasing pattern; the lowest value was 19.257 and the highest value was 65.297 (Fig. 7). Considering the range of CO2 concentrations, the RMSEs were not high. However, the RMSE of the last output is three times higher than the first output, so another cost function would be required to conduct regression using the LSTM (Wen et al., 2015). The costs of outputs were calculated simultaneously, so the model can only deal with the sum of the costs. To train the LSTM regressor, sequence-independent values should be studied. However, the LSTM showed adequate accuracy in prediction of CO2 concentrations, so the trained LSTM can be used to predict the future CO2 concentration and applied to efficient CO2 enrichment for photosynthesis enhancement in greenhouses. In this study, the greenhouse CO2 concentrations could be relatively well predicted. To ensure that the trained LSTM is applicable to all cultivation conditions, the model should be applied to and verified at other cultivation sites.